 dmitshur
dmitshur
I enjoyed seeing the A half-hour to learn Rust blog post by Amos recently. For someone like me who doesn't know Rust but is curious about it, it felt like a very accessible introduction that I could use to learn Rust.
One of my absolutely favorite properties of Go is how short and simple the language is. My previous primary language was C++. Go has comparatively few keywords and language features, and yet I never feel something is missing when I'm writing Go code. On the contrary, I feel very productive as a programmer when getting things done using Go, and I really appreciate that it's simple to learn and teach. After using it for non-stop for over 7 years, writing Go still brings me joy like no other programming language I've ever used. I certainly wouldn't recommend Go to someone who wants a complicated programming language, but I would if one wants a simple and productive one.
So, reading that blog post made me very curious to try a quick experiment. What would the same post look like if it were written about Go instead?
I figured I'd give it a shot.
Ready? Go.
var declares a variable of a given type:
var x int // Declare x of type int.
x = 42 // Assign 42 to x.
This can also be written as a single line:
var x int = 42
You can also specify the variable's type implicitly:
var x = 42 // Type int is inferred from 42.
This can also be written using a short form:
x := 42
You can declare many variables at the same time:
var a, b, c int
a, b, c = 1, 2, 3
x, y := 40, 80
All declared variables are always initialized to the zero value. If you declare a variable and use it right away, you can be sure it'll have the zero value of that type.
var x int
foo(x) // Same as foo(0).
The underscore _ is a special identifier. It's used to indicate "no identifier" and can be used to discard something, or mark …
- dmitshur
Did you learn that macOS 10.14 and newer has marked its OpenGL API support as deprecated?
Are you interested in giving Apple's Metal API a try?
Are you a fan of Go and don't feel like switching to Swift or Objective-C for this?
Then this post is for you.
By the end of this post, we'll render a single frame with a colorful triangle using Metal. We'll render to an off-screen texture, and then copy its contents into an image.Image for further inspection.
I'll focus more on the Go code to make this happen. If you're not already familiar with the general principles of modern low-level GPU APIs such as Metal, Vulkan, Direct3D 12, it's a good idea to learn more about them first. There are lots of resources on this topic, and they're easily findable. For Metal specifically, I can recommend watching the Metal for OpenGL Developers session from WWDC18 that gives a pretty good overview, especially for those who are familiar with OpenGL.
General approach
Metal API is officially available in Objective-C and Swift variants. We will use cgo, which allows calling C code from Go, to use the Objective-C Metal API. A wrapper Go package can be created, exposing Metal as a convenient Go API.
I've already started a Go package for this at dmitri.shuralyov.com/gpu/mtl, and I'll be using it below. It's in very early stages of development though, so its API is going to evolve over time. You're welcome to use it as is, as a starting point for your own version (i.e., fork it), or just for reference.
Hello Triangle high-level overview
At a high level, there are 10 steps we'll follow to render the triangle:
- Create a Metal device…
- dmitshur
(This post was originally posted as part of the GopherAcademy Advent 2017 series.)
In this post, I will tell a story of how I had to build a custom JSON unmarshaler for the needs of a GraphQL client library in Go. I'll start with the history of how everything started, build motivation for why a custom JSON marshaler was truly needed, and then describe how it was implemented. This is going to be a long journey, so strap yourself in, and here we go!
History of GraphQL Client Library in Go
GraphQL is a data query language for APIs, developed internally by Facebook in 2012, and made publicly available in 2015. It can be used as a replacement for, or in addition to REST APIs. It some ways, it offers significant advantages compared to REST APIs, making it an attractive option. Of course, as any newer technology, it's less mature and has some weaknesses in certain areas.
In May of 2017, I set out to build the first GraphQL client library for Go. Back then, only GraphQL server libraries existed in Go. My main motivation was wanting to be able to access GitHub GraphQL API v4 from my Go code, which had just come out of early access back then. I also knew that a general-purpose GraphQL client library would be useful, enabling Go projects to access any GraphQL API. There were GraphQL clients available in other languages, and I didn't want Go users to be missing out.
I spent a week on the initial investigation and research into what a Go client for GraphQL could look like. GraphQL is strongly typed, which is a good fit for Go. However, it also has some more advanced …
- dmitshur
I saw a message in Gophers Slack #general chat that stood out to me:
but running
gofmtin the browser is, um, hard
The context was that they had a 100%-client-side JavaScript application that produced some Go code, but the Go code wasn't gofmted.
"Wait a minute, that's not hard," I thought. "It's trivial! Getting gofmt to run in the browser? I bet I could do it in 10 lines of code!"
Right?
Then I realized. It's not trivial. It's not obvious. It just seems that way to me because I've done a lot of things like this. But many people probably haven't.
So that inspired me to write this blog post showing how you, too, can have gofmt functionality running in the browser alongside your JavaScript code very easily. The only thing I'll assume is you're a Go user and have a working Go installation (otherwise, you're unlikely to be interested in gofmt).
gofmt has relatively complex behavior, so how can it all be implemented in just 10 lines? The trick is that we don't have to rewrite it all from scratch in JavaScript. Instead, we can write it in Go, as that'll be much easier.
To get Go to run in the browser, we'll use GopherJS. GopherJS is a compiler that compiles Go into JavaScript, which can then run in browsers. We'll use two Go packages:
go/formatpackage of the Go standard library. It exposes all of the functionality we need to havegofmtbehavior.github.com/gopherjs/gopherjs/jspackage. If you've ever used cgo and didimport "C"to interface with the C world, it's very much like that, except the semantics are more like thereflectpackage. In the end, it lets you access and modify things in the JavaScript world.
Building JavaScript that implements gofmt
So, let's get started. I am assuming you already have the current version of Go in…
- dmitshur
This is obviously inspired by the recent Replacing Disqus with GitHub Comments post on HN.
I wanted to share something similar I've done with my blog. You're looking at it now. It's not using Disqus or any heavyweight 3rd party solution for comments.
Instead, I've created something very simple, similar to GitHub Issues frontend UI and backend, and used that. The backend is completely pluggable (it's an interface), so it can be implemented by talking to real GitHub API, or any custom implementation you want. My blog uses a simple JSON files implementation, so I can avoid a heavyweight database dependency.
When I first created it, I was using yet another issues.Service implementation that was exposing my original WordPress blog (via its export as XML functionality). But eventually I migrated that into the current filesystem-backed store, which lets me edit and create new blog posts easily.
Oh, and I've also implemented reactions. Not just 6, all of them.
You're welcome to test out comments here, similar to https://github.com/dwilliamson/donw.io/issues/1. I rely on GitHub for authentication (I didn't want to make people come up with yet another password).
(Update on 2020-03-02: By now, you can also sign in via IndieAuth or RelMeAuth. See issue 34 for details.)
- dmitshur
Have you ever had a piece of Go code like this:
// TODO: Get rid of this global variable.
var foo service
func fooHandler(w http.ResponseWriter, req *http.Request) {
// code that uses foo
}
func main() {
foo = initFoo()
http.HandleFunc("/foo", fooHandler)
}
One way to get rid of that global variable is to use method values:
type fooHandler struct {
foo service
}
func (h fooHandler) Handle(w http.ResponseWriter, req *http.Request) {
// code that uses h.foo
}
func main() {
foo := initFoo()
http.HandleFunc("/foo", fooHandler{foo: foo}.Handle)
}
Of course, net/http also has http.Handle so in this case you can simply change fooHandler to implement http.Handler interface:
type fooHandler struct {
foo service
}
func (h fooHandler) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// code that uses h.foo
}
func main() {
foo := initFoo()
http.Handle("/foo", fooHandler{foo: foo})
}
But method values are great when you need to provide a func, for example in https://godoc.org/path/filepath#Walk or https://godoc.org/net/http#Server.ConnState.
- dmitshur
Last night I got a chance to setup and spend a few hours with the long-awaited first consumer version of the Oculus Rift (aka Oculus Rift CV1). I'll describe my experience in some detail.
Background
This is not my first time trying on a VR headset. I've tried the first developer kit (DK1) a long time ago, but only for a few minutes. It was compelling enough to make me understand that the final release, scheduled a few years off at the time, would be incredible, but of course there were a few "must fix this and must make that better first" items remaining. I had to use my imagination to predict what it'd feel like in the end. I tried two experiences: a pretty basic unexciting demo of pong in 3D, and a virtual walkthrough through Japan in the form of a 360 video. The latter was great for making me feel the presence factor and ability to experience an exotic real-world location.
Some time later, I tried the second dev kit (DK2) with a pretty sweet experience. There was a demo booth at a movie theater that was playing Interstellar, and they had a 5-8 minute Interstellar-themed experience. You sat in a nice, comfy chair, they put on the DK2 and a pair of high-quality headphones, and you were transported into a situation on board of a futuristic spaceship. It was a high-budget demo, so the 3D environment was professionally made with lots of detail. You could look around, and primarily, you could feel the sense of presence... Actually being in that spaceship, and exploring what it had to offer. My favorite parts were the section where they made you feel weightlessness. With a countdown from 3, the experience creators used a combination of motion, a "whoosh" sound, and the chair you were sitting in slightly dropping down, to very convincingly make you feel that suddenly gravity was turned off. The other part I loved was the end, where you got to a very detailed cockpit of the spaceship, complete with many controls, buttons, joysticks. When you looked out the windows…
sqs
Dmitri Shuralyov (dmitshur) was one of the first users of Sourcegraph whom we didn't personally know. We've enjoyed meeting up with him over meals and seeing him at all of the Go meetups in San Francisco. He is the quintessential early adopter—and creator—of new kinds of development tools, such as Conception-go (a platform for dev tools experimentation) and gostatus (which lets you track changes to a whole GOPATH as if it's a single repository). He's bringing the Go philosophy to other languages, starting with markdownfmt (gofmt for Markdown).
We talked with Dmitri to learn about his sources of programming inspiration, and to hear about his current Go projects.
How and why did you start getting involved in open source programming?
I'm no stranger to using closed source software over the years. Some of it is really nice, and I enjoy using it. But as someone who writes code, I inevitably want to make it even better, fix bugs or contribute in other ways. But I can't do that unless the project is open source.
For all my personal projects, I always default to making them open source. Just because if someone out there likes it and wants to help out and make it better, I want to welcome that instead of denying them that opportunity.
In addition to that, I strongly believe in the benefits of code reuse, and open source libra…
- dmitshur
First off, I want to make it clear I have a fixed GOPATH that I do not change per project. The GOPATH env var is set inside my ~/.bash_profile file and doesn't change. Every Go package I have exists in no more than one place. I tend to have all my personal dependencies on latest version, simply because it's easier to have everything up to date than any alternative.
I do make use of the fact that the GOPATH environment variable is defined as a list of places rather than a single folder.
From https://golang.org/cmd/go/#hdr-GOPATH_environment_variable,
The GOPATH environment variable lists places to look for Go code. On Unix, the value is a colon-separated string. On Windows, the value is a semicolon-separated string. On Plan 9, the value is a list.
My GOPATH consists of 3 folders or GOPATH workspaces.
The first one is my landing workspace. Since it's listed first, whenever I go get any new package, it always ends up in this workspace.
Go searches each directory listed in GOPATH to find source code, but new packages are always downloaded into the first directory in the list.
I make it a rule to never do any development in there, so it's always completely safe to clean this folder whenever it gets too large (with Go packages I don't use). After all, it only has Go packages that I can get again with go get.
My second workspace is for all my personal Go packages and any other packages I may want to "favorite" or do some development on. I move things I use regularly from first workspace into second.
My third workspace is dedicated to the private Go packages from my work, and their dependencies. It's convenient to have my work packages separate from all my personal stuff, so they don't get in each other's way.
With that setup, multiple GOPATH workspaces feel a lot like namespaces. The reason I have more than one, to me, is quite similar why one might want to break a medium-sized Go package into several .go files. The result is effectively …
- dmitshur
As a kid, growing up, it seemed like math was a solved problem. It'd be very hard to invent something new, because so much has already been done by others. You'd have to get to a very high level, before you could go somewhere where no one has gone before.
In software development, it feels like the opposite situation. There are so many basic things that are currently unsolved and not possible. But they can be made possible with just some effort spent on it.
Here are some open questions that I can think off the top of my head (using the Go language for context):
- What is the name of a variable, at runtime? (Solved)
- What is the source code of a function, at runtime? (Solved)
- What are all the variables accessible within the current scope (where the caret is)?
I'll add more as I run into them.
- dmitshur
When understanding code, we build gigantic mental dependency graphs relevant to the task at hand. This requires much focus, time, memory.
— Dmitri Shuralyov (@dmitshur) February 14, 2013
Building these dependency graphs in your head from code is very intensive mentally, that's why programmers cannot take interruptions.
— Dmitri Shuralyov (@dmitshur) February 15, 2013
So when you're "in the zone" being very productive, it's because this graph is built. You know what will be affected when you change stuff.
— Dmitri Shuralyov (@dmitshur) February 15, 2013
The problem with that approach is you're storing valuable, hard to build information in your short term memory. Next morning it'll be gone.
— Dmitri Shuralyov (@dmitshur) February 15, 2013
If another person reads your code, they will not benefit from anything you've come up with in your mind. They will have to redo this work.
— Dmitri Shuralyov (@dmitshur) February 15, 2013
Optimize for how humans think and change things as a visual graph, not how computers used to store bytes 40 years ago as plain text files.
— Dmitri Shuralyov (@dmitshur) <a href="https://twitter.com/dmitshur/status/302…
- dmitshur
A friend shared the following article on Lifehacker about Otixo, a "Convenient File Manager for Dropbox, Google Drive, SkyDrive, and All Your Other Cloud Services," and it made me realize something.
It seems most products/services these days, and the accompanying articles describing them, follow a similar model:
"Create something that doesn't exist to solve some problem, or make some task easier."
In this specific case, they figured if a person has >1 cloud storage, managing them separately is hard so it'd make sense to create a unified interface that allows you to do that. And that's great!
However, I've found that recently (only within the last year or two, I think some time after I got my iPhone) I've started to look for another way to solve problems: by simplifying. I figure out what's essential to me, and try to throw everything else out.
So if I need to have cloud storage, there are 2 paths:
- Get Dropbox, Google Drive, SkyDrive, etc.
- Then get Otixo to help manage/unify them and make your life easier
or
- Choose the best single service, use only it
The advantage of path 1 is you get more space, but it involves more things. However, if u can get by with path 2, it involves less things, which I appreciate (more so than having that extra space, cuz right now 24 GB of free Dropbox is way beyond what I need).
My point is this: it seems my line of thinking (simplifying) is rather under-represented in terms of human efforts. How many people are working on products/services/writing articles about how to simplify, throw things out? Seems like very few.
If you want to improve your life and solve problems by simplifying, you gotta do it on your own. If you wanna solve problems by adding things, just go to lifehacker.com and such.
- dmitshur
Apple is known as a company that strives for perfection in everything they do. They place a lot of attention on getting the smallest of details right. The little things that you rarely notice, not until you see someone else doing it wrong.

This attention to detail shows up everywhere. Take the power indicator on a MacBook for instance. It is meticulously programmed to light up in a solid white color only when the following two conditions are met:
- The MacBook is turned on
- Its LCD screen is not lit up
This ensures you can tell whether the computer is turned on at all times, yet the indicator light is never on when it would be redundant. After all, if the LCD is on, you will already know that the computer is on.
iOS is a fine example of high-quality Apple software. It's not always perfect, but the level of polish is above and beyond what you typically find in this very young but fast growing mobile industry. However, one of the side-effects of highly polished software is that when there are flaws in it, they become quite glaring in contrast to everything else that is done well.
There is one such flaw that I've found. Being able to tell the time on your phone is quite important, that's why it always takes its place front and center in the middle of the status bar.

When an iPhone is locked, time and date are displayed in a large font. To avoid displaying the time twice, needlessly, time within the status bar is replaced by a small lock icon.
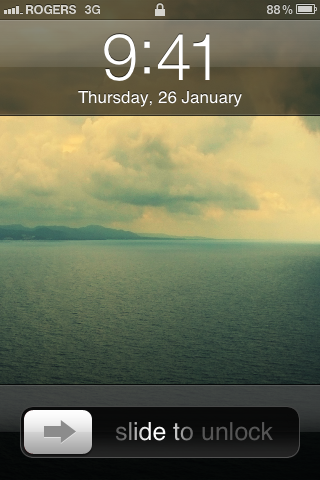
The problem occurs when you get a call while your device is locked.
[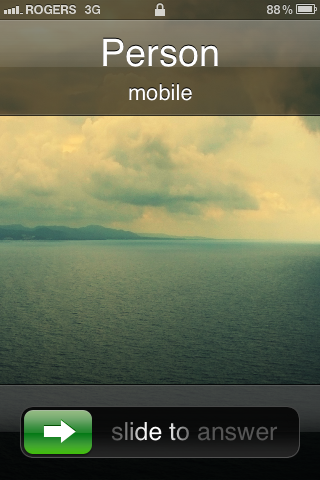 ](/usercontent/1924134@gi…
](/usercontent/1924134@gi…
- dmitshur
I got my trusty CRT monitor capable of high refresh rates from the basement, to try my recent motion blur demo on it. It looked great on my 60 Hz LCD, so I had high expectations for 120 Hz.

I was shocked with the outcome. As expected, going from 60 to 120 Hz made a huge, noticeable difference in my demo with motion blur off. But turning it on, there was no significant difference. For the first time, I couldn't believe my eyes.
As a competitive gamer and someone very passionate about display technologies, I am very familiar with the concept of refresh rate. The more, the better, I always thought. 60 Hz is okay, but 120 is much better! I could always easily tell the difference. Until now.
After thinking about it, it made sense. This is probably the root of all "but the human eye can only see at most X frames per second" arguments on the internet. It matters what the frames are, or more precisely, how distinct they are. I can easily tell the difference in frame rate when they are very distinct, but I wasn't when motion blur made them less so.
You can experience the motion blur demo for yourself if you have a WebGL-capable browser.
The examples are abundant. Take movies. At 24 frames per second, the motion looks acceptably smooth. But take any video game running at 24 frames and it's unplayable. The difference is in motion blur. Each frame in film captures the light for roughly 1/24th of a second. In a video game, each frame is typically rendered as if with instant exposure time. For these type of frames, yes, the higher the frame rate, the smoother the motion appears.
I am planning to confirm my findings on a 120 Hz LCD monitor soon, but I am certain that the results will be similar.
- dmitshur
"By avoiding a future arrow from hitting your present self, you ensure your past self will dodge the present arrow."
Suppose you are designing a networking system for a multiplayer game. One of the biggest factors in the quality of networking design is how smooth the game feels for its players. People are not happy when they see snapping, jittering or other unexpected non-smooth behaviours. Such things occur because of the latency over the internet, and games have to try to predict things that are unpredictable by nature (e.g. player movement). Each time the prediction is wrong, the user sees an unpleasant correction.
One way to reduce such negative effects is to try to mask the corrections, by using smoothing.
I propose another approach. We can try to rely less on information that is uncertain, and rely on what is known. The latency is still there, but we can work around it.
Imagine an internet game server with multiple players, where everyone has less than 100 ms round-trip latency (and under 50 ms single-way latency). Those are good internet conditions, but not too unrealistic for today.
That means each player can know exactly all other players have been 100 ms ago, without having to use prediction. Let's render them there. The local player still sees himself at present time, but he sees all other players 100 ms in the past, 100% smoothly (ignoring dropped packets).
We want to let players aim at enemies, and not where they think enemies are due to their current latency (ala Quake). So the server performs hit collisions with regard to what the player shooting saw. Bullets travel in present time, but they collide with players' positions 100 ms in the past.
All the above has been done before (see Half-Life 1). But here's the kicker of this post.
What if you try to dodge a bullet by doing something within 100 ms of it hitting you. With the above system, you physically can't. No action, however drastic, within 100 ms of the bullet hitting you can …
- dmitshur
You are riding the subway. It's a regular train car. It feels familiar. There aren't many people. Some are reading newspapers. A woman takes a sip from her coffee cup. An older woman in a wheelchair waits patiently for her stop. The train moves silently, as if through a thick layer of fog.
It makes a stop and a male gets on.
The train continues its monotone passage through a moonless night. It's smooth sailing under the stars, except they're not visible from within the tunnel.
A man in the seat ahead talks out loud, either to himself or into a headset. More likely the former.
People continue to mind their own business, each one almost completely oblivious to the presence of others.
An empty coffee cup rocks back and forth under the seat in front, caressed gently by the soft ride.
Another stop. The next station is Eglinton. They become more frequent, each one seemingly marking a period at the end of a sentence in the lifetime story of the train.
Three girls chatter happily at the end of the train car. Some laughter is heard from the other end. As I near my destination, my heart rate goes up ever so slightly. The smell of excitement fills the car.
The night is young. Whatever adventures await ahead are still unwritten.
- dmitshur
Suppose you have an ideal piece of software at version X with one bug in it. When the developer fixes the bug in version Y, you want to have that bug fixed too.
Without automatic updates, this means you have to manually update to Y. This has some cognitive effort associated with it. When multiplied by hundreds of different pieces of software, it is quite significant.
Wouldn't it be better to have it automatically update without the end user having to worry about or even know anything about versions? Yes and no:
- Yes - if you don't mind using the newer version and the update process
- No - if the new version does something other than bug fixes (i.e. added/removed features)
- No - if the autoupdate process is intrusive and slows down your computer
I think the reasons for the 'no' answer can be, in theory, avoided, leaving yes and therefore making it possible to reduce cognitive load. To make our lives simpler by not having to regularly update software or deal with a major update from a very old version.
- dmitshur
I think there is a lot of untapped potential for online games. I mean something else altogether.
Most online games right now are perfect simulations, or rather they attempt to be. Most online games imply multiplayer. Each player connected to the same server will be a part of the same virtual world. What player A sees going on is very close to what player B sees (albeit from a different perspective).
Let's break that constraint. Suppose there is an online multiplayer game where two players are connected to the same server, yet they live and interact in two completely different realities. Think about the doors this opens. The opportunities are endless. However, not many of them would make fun games. But I believe there may be something worthwhile out there. We just have to explore this direction a bit.
There already are some examples of this situation happening. Take a RTS game that is peer-to-peer. Imagine for some reason the two players go out of sync. At this point, they may both think they are winning the battle. There will be two winners and no losers, and each may have a lot of fun... until they realize their games are not in sync (via talking), where that fun will quickly end and frustration will set in.
But that's only an example of a broken simulation. The multiplayer RTS game was designed to be in sync, not out.
Let's look at online games that were designed to be not in sync.
I remember in a multiplayer FPS America's Army, there were 2 teams of players fighting each other. The game was made so that whichever team you picked, it would appear as the "good guys" and the other team is the "terrorists." This is a very minor visual aspect that has no gameplay value whatsoever. Maybe it wasn't even worth mentioning. ;)
As all good writers do, I'm leaving the best example for the last. There is a short simple indie game called 4 Minutes and 33 Seconds of Uniqueness. Assuming you don't mind the f…
- dmitshur
There's a conflict of interest. I've just realized this, but I think I see what it is that makes some stories or people interesting to hear and some not.
It's a conflict of interest. When you are the one telling the story, a story you're excited about and want to convey it in the most interesting way possible. You don't want to give away any spoilers that will ruin it. So you take your time and explain everything in detail. Because that's how you would've liked to hear it, or so you imagine. The only reason you wanna hear it that way is because you already know everything, and now you're just going over it the second time.
Other people, on the other hand, have absolutely no idea what your story will be about. They want to know right away. You could tell them in one sentence, but you wouldn't feel satisfied with that. You want to paint the story in its full colours and detail. But other people want to know it as soon as possible. They would love to hear all the details if they already knew the big picture.
I guess the problem is that communication using words takes time; it's not instantaneous. If it were, we'd have no problems.
Personally, I don't even like the idea of movie or book titles, because they give away some of the surprise for me. Yet I want to know in advance if the movie or book will be interesting to experience. It's a conflict of interest.
I'm sure I could've worded this exact idea in just a few sentences, but I haven't. Why? I don't know, it's hard, and it's something I'll have to think about more and hopefully work on.
- dmitshur
This post is way overdue, and it is a perfect example of what I'm about to talk about.
I'm not very good at English writing or clearly and consicely expressing my thoughs in words. Yes, here I am talking about my weaknesses, and you're thinking why should you even continue reading what this guy has to say.
But it's ok, because I don't care. In a good way.
See, I have this theory that allows me to think that it's ok for people to be wrong or bad at something. At least, it shouldn't stop them from working on what they love (as long as it doesn't negatively impact others).
The reason for that is since there are many people, there's nothing wrong with them fanning out and trying to work in different directions (think of a non-deterministic Turing machine). Some will be right, some wrong. The alternative is catastrophic: groupthink. If everyone were to try ony one approach, then everyone is simply screwed if the group's consensus is wrong.
Consider the following example. At some point, people thought the Earth was flat. If not for the person/people who dared to go against the flow, perhaps we would never have discovered otherwise.
Hence, I believe that no matter how wrong or stupid something I'm doing may seem to others, I have perfect grounds to stick with it if I believe it to be the right thing.
Of course, this doesn't mean I will ignore all constructive critisim. On the contrary, I will happily consider all such feedback, and try to adjust if I see the error of my ways.
As far as my posts go, basically, I have two choices. Either care a lot about my spelling/grammar/presentation, spend too much time editing my posts until I believe they are ready for mass (lol) viewing, and post rarely. Or, not pay much attention to that stuff, but rather post things as they come to my mind with little editing or rewriting. This will allow me to actually use this blog the way it's meant to be. I hereby choose the latter.
- dmitshur
There are a bunch of topics that are of high interest to me, and I'll be using this blog to talk about some of them.
My main passion and a dream job is no doubt game development. This will likely be the main subject of this blog, as well as other computer related topics. However, I'm also into things like psychology, philosophy, HCI/User Interfaces, physics, racing, driving, snowboarding, longboarding, RC cars, racing simulators, displays, pixels, portable devices, in arbitrary order.
I like cars in general, and anything that has to do with driving, racing or making them. One of my long term dreams has always been to create a playground realistic driving sim where I'm able to experiment with various car designs. Until then, I have LFS. I also tend to play around with some remote controlled cars that I have.
I also like to delve into contemplations about the meaning of life, and other philosophy/psychology questions. I might post some of my ideas on that here.
Anyway, I doubt I will talk about every single of my interests here, so perhaps throwing all those tags out wasn't the best idea. Oh well.
- dmitshur
So I've finally decided to create a blog. I will be posting things related to my various interests here.
I know I'm kinda throwing this out into a void here, but that's ok for now. It might a good outlet for me to get my ideas out and to think about them as I do. After all, it can't hurt, can it?